
Designing a Developer-First Data Layer for B2B SaaS
Build API-first, modular, secure data layers that let developers integrate in minutes—covering contract-first specs, ingestion, modeling, activation, and observability.

In B2B SaaS, a developer-first data layer prioritizes APIs as the core product, not an afterthought. This approach revolves around creating a machine-readable API contract (e.g., OpenAPI or AsyncAPI) before coding begins. By focusing on developer experience (DX), you enable faster integrations, reduce churn, and streamline development. Key benefits include:
Parallel Development: Use mock servers to let frontend and backend teams work simultaneously.
Consistency: Standardized patterns, predictable error handling, and clear documentation.
Scalability: Modular architectures with API gateways, orchestration layers, and service integrations.
Security: OAuth 2.1, granular permissions, and tenant isolation for data protection.
A well-designed data layer ensures developers can make their first API call within minutes, improving satisfaction and boosting retention. The article explores principles like API-first design, modularity, and robust security to build scalable, flexible systems that integrate seamlessly into customers' workflows.
Why you should be doing contract-first API development | DevNation Day: MAD
Core Principles of Designing a Developer-First Data Layer
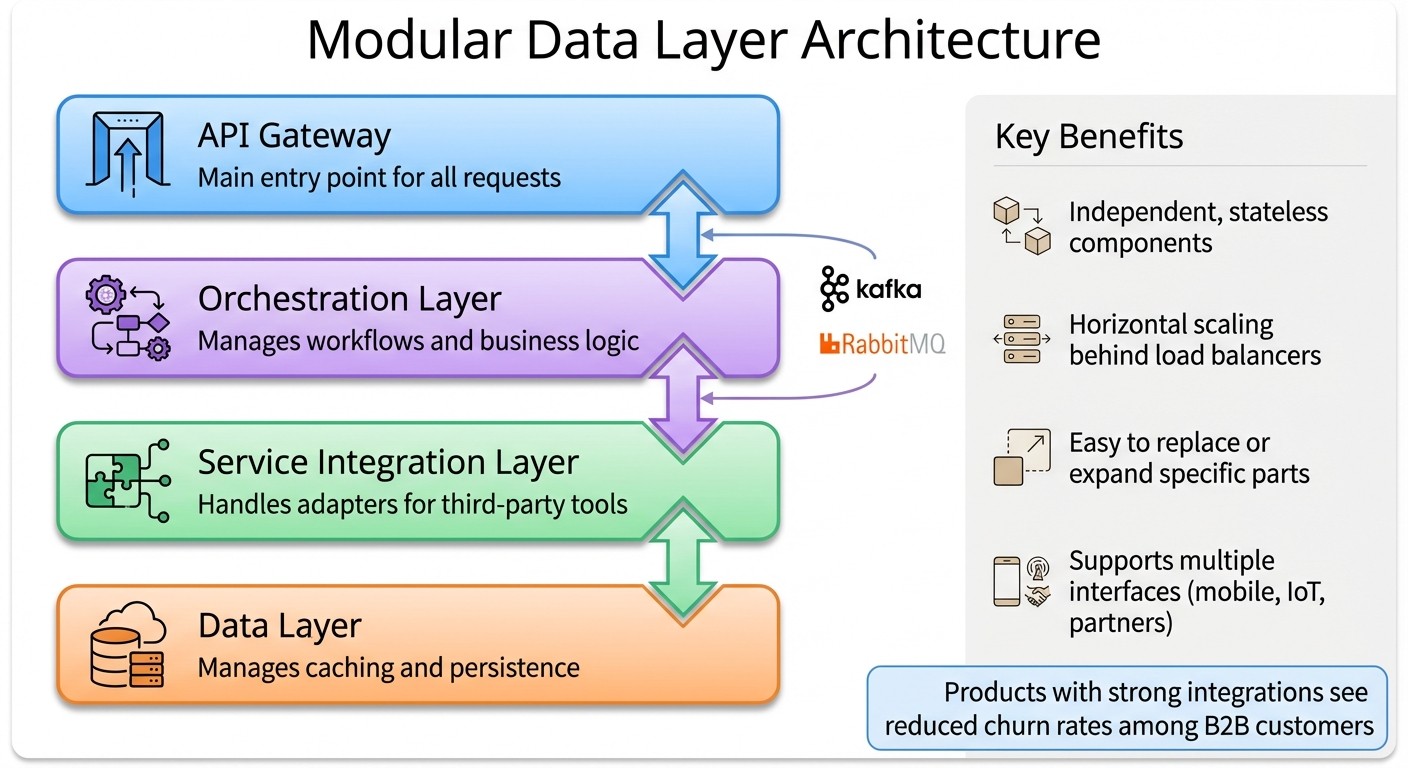
Four-Layer Architecture for Developer-First B2B SaaS Data Systems
When it comes to building a data layer that developers genuinely want to use, three key principles stand out: API as product, scalability, and security. These aren't just technical considerations - they're strategic choices that can make your B2B SaaS platform indispensable.
API-First Approach
The API-first approach flips the traditional development process. Instead of building application logic first and adding an API later, you start with the API contract. Using tools like OpenAPI 3.1 or AsyncAPI, you define endpoints, data schemas, and authentication flows right from the start. This machine-readable spec becomes your single source of truth.
The benefits are hard to ignore. At least 75% of developers in API-first companies report being happier, more productive, and quicker to launch products. With this approach, frontend teams can use mock servers generated from the API spec while backend teams work on the actual implementation. This eliminates delays and keeps everyone on the same page.
To ensure a smooth developer experience, your API should feel polished from the very first call. Use consistent naming conventions, standardized error handling, and provide SDKs in popular languages like Python, Ruby, and Node.js. Given that 51% of developers say over half of their organization’s development effort goes into APIs, consistency and quality here are non-negotiable. This approach also sets the groundwork for creating modular systems.
Modularity and Scalability
A modular data layer allows your system to be broken into independent, stateless components that can scale horizontally behind load balancers. This design makes it easy to replace, expand, or scale specific parts without having to overhaul the entire architecture.
Typically, this architecture includes four layers:
API Gateway: The main entry point.
Orchestration Layer: Manages workflows.
Service Integration Layer: Handles adapters for third-party tools.
Data Layer: Manages caching and persistence.
For tasks like data exports or batch processing, asynchronous tools like Kafka or RabbitMQ can handle the workload. For example, when a developer triggers a large report, your API should return a job ID immediately while processing the request in the background.
This modularity also simplifies adding new interfaces - be it mobile apps, IoT devices, or partner integrations - without reworking the backend. Products with strong integrations often see reduced churn rates among B2B customers. Once a customer builds deep integrations into your platform, they’re far less likely to switch.
While modularity ensures flexibility, security is what keeps the entire system trustworthy.
Security and Data Governance
Security must be built into every layer. With over 39 million secrets leaked in 2024, relying on static API keys is a significant vulnerability. Instead, use OAuth 2.1 for machine-to-machine authentication, relying on short-lived tokens that can be revoked instantly.
Centralize your authorization logic by using a Policy Decision Point (PDP) with declarative languages like Cedar or Rego from Open Policy Agent. This avoids scattering conditional checks throughout your code and enforces rules like tenant-specific access boundaries.
Tokens should follow the principle of least privilege, with granular scopes like "read:users" instead of broader permissions like "admin:billing". This minimizes the damage if a token is compromised.
Maria Paktiti, an engineer at WorkOS, sums it up perfectly:
"API security isn't just about avoiding major failures - it's about designing with intention, reducing risk, and building trust into every layer of your system".
Additional safeguards include field whitelisting in API responses to control what data gets returned, parameterized queries to prevent injection attacks, and rate limiting by user or token instead of just IP address.
For B2B SaaS platforms, tenant isolation is essential. Even on shared infrastructure, you need mechanisms to ensure that one customer’s data is completely inaccessible to others.
Key Components of Developer-First Data Architecture
A developer-first data architecture builds on principles like API-first design, modularity, and security, focusing on three key areas: ingestion, transformation, and presentation.
Source Ingestion Layer
The ingestion layer captures raw data directly from external sources such as CRMs, marketing platforms, and analytics tools. By storing this data "as-is", you maintain the ability to trace back to the original source for debugging or audits.
To prevent system overload while keeping data current, use incremental updates instead of pulling all data repeatedly. This can be achieved with change logs or modified timestamps.
Modern setups prioritize security, supporting protocols like OAuth 2.0 for user-delegated access, JWT tokens for microservices, and mTLS for enterprise-grade security. Charles Wang, Lead Product Evangelist at Fivetran, highlights the importance of high-quality APIs:
"As a SaaS provider, you owe your users the opportunity to make the most of the data they generate in your product. A high-quality API gives your users the means to integrate their data with a rich, modern, cloud-based data ecosystem."
To streamline development, standardized ingestion patterns can save time. For example, webhook receivers can immediately push incoming data into a messaging system like Kafka. This prevents data loss during system crashes. Pagination is another useful strategy for full syncs, helping to manage API response sizes efficiently.
Data Transformation and Modeling Layer
Once data is ingested, the transformation layer organizes it into a structured, business-ready format. This involves schema validation, normalizing inconsistent fields, and creating reusable models tailored to your business logic. Breaking transformations into distinct stages - raw staging, validation, and enriched production models - ensures clarity and purpose at every step.
Tristan Handy, Founder & CEO of dbt Labs, compares this process to software development:
"Analytical systems are software systems. Therefore, in developing large-scale, mission-critical data systems, many of the best lessons that can be learned come directly from software engineering."
This means writing transformations in readable code (like SQL or Python), managing them in version control, and implementing a robust testing framework. Use unit tests for logic, data tests for validation, and integration tests to assess system-wide impacts. Keeping your code modular and adhering to the DRY (Don't Repeat Yourself) principle can simplify maintenance as your system grows.
Data enrichment is another critical step. For instance, B2B data can decay at a rate of 25% to 30% annually, making continuous enrichment essential. Enriched data leads to better outcomes - B2B leads enriched with additional details convert 20% to 30% more effectively. The market for B2B data enrichment is expected to grow from $5 billion in 2025 to nearly $15 billion by 2033.
Data Point | Before Enrichment (Raw) | After Enrichment (Actionable) |
|---|---|---|
Title | Unknown | VP of Marketing |
Industry | Unknown | SaaS |
Tech Stack | Unknown | Salesforce, Marketo, Google Analytics |
Recent Funding | Unknown | Raised $50M Series B (3 months ago) |
For platforms integrating multiple APIs, adopting a unified common data model simplifies normalization, making it easier to work with structured data without mastering every unique API.
Presentation and Activation Layer
The presentation layer focuses on delivering processed data to end-users, applications, and AI models in formats optimized for usability. This is where developer experience takes center stage. Instead of rigid endpoints, offer flexible interfaces like GraphQL for custom queries or gRPC for high-performance microservices. These options reduce friction and align with a developer-first mindset.
For real-time needs like personalization or live dashboards, low-latency access is essential. Event-driven processing, rather than nightly batch updates, ensures data is always up-to-date. Bianca Vaillants, Sales Development Representative at BIX Tech, emphasizes this urgency:
"If your AI is reacting to yesterday's data, you're already behind. Real-time processing shifts the default from 'update nightly' to 'update now'."
Efficient data activation also involves sending high-quality insights back into operational tools like CRMs and marketing platforms. This creates a feedback loop, allowing insights to drive immediate actions in the tools teams rely on daily.
Emerging "lakehouse" architectures are gaining traction, combining streaming, unstructured data, and machine learning workloads into a unified core. This approach supports diverse use cases, all from a single presentation layer, making it easier to adapt to evolving demands.
Implementation Best Practices for B2B SaaS Data Layers
Turning solid architecture principles into actionable implementation requires focusing on three key areas: schema design, pipeline automation, and system observability. These elements play a major role in determining whether your data layer becomes a strategic asset or a constant headache.
Unified Schema Design
A unified schema helps eliminate inconsistencies between vendors. Before diving into code, it's crucial to align teams - marketing, analytics, and development - on the exact data requirements. Once that’s done, create a vendor-neutral mapping to standardize data formats across APIs. For instance, if Adobe Analytics uses prop1 and Google Analytics uses pageType, map both to a common page_type field.
Stuart Roskelley, a Software Engineer, highlights the importance of upfront planning:
"The data layer is a core piece of your software that will help drive decisions for your business. The more planning up front you can do before implementing, the more time you'll save down the road."
For B2B SaaS platforms with multiple clients, multi-tenant isolation is essential. Add a tenant identifier to every table to ensure data separation, and use database-level row security policies to enforce it. Modern databases like PostgreSQL can handle tens of thousands of transactions per second when configured properly.
Stick to W3C naming conventions: use camel casing (e.g., dataLayer), avoid spaces, and don’t begin property names with numbers or special characters. Clear documentation for every key and attribute, especially primary and foreign keys, is a must - it saves developers from unnecessary guesswork. For simpler transformations, SQL aliasing with AS statements can handle renaming and format changes without complex code.
Pipeline Flexibility and Automation
Once your schema design is solid, your pipelines need to be flexible and automated to handle changes effectively. Build them to operate independently, so you can tweak tools or logic without disrupting the entire system. Instead of procedural code for every API, use declarative orchestration to specify what data you need without detailing how to fetch it.
In 2024, Cox Automotive (the company behind AutoTrader and Kelley Blue Book) used Apollo Connectors to simplify a complex REST-based VIN decoding service. What was initially planned as a year-long project was completed in just two days using declarative mapping. Mark Meiller, Principal Engineer of Data Services, shared:
"Complex vehicle data logic that would have required extensive rewriting – and frankly, was seen as an insurmountable task – is now transformed into a few lines of declarative code."
Adopt incremental updates with Change Data Capture (CDC) to process only new or modified records using change logs or timestamps. For webhook-driven systems, use triggers like sync.complete to ensure downstream data stays current in near real-time. Be mindful of upstream vendor rate limits to avoid 429 errors.
Automated schema management tools can sync changes from source APIs, preventing pipeline failures when APIs evolve. Without automation, data teams spend up to 69% of their time on repetitive tasks. By prioritizing self-serve analytics and automation, you free up resources for more strategic work.
Monitoring and Debugging
Streamlined pipelines are only as good as the monitoring systems that back them up. Effective monitoring ensures reliability and quick issue resolution. Instead of tracking every table, group data into priority levels: P1 for critical systems and user-facing products, P4 for lower-impact exploratory analysis. This helps focus resources where they’re needed most. Define Service Level Indicators (SLIs) across six dimensions: Accuracy, Completeness, Consistency, Uniqueness, Timeliness, and Validity.
At Aiven, Data Engineering Manager Stijn managed over 900 dbt models by grouping assets into domains like "Attribution Marketing" (P1) and "Market Research" (P3). This approach reduced circular dependencies and sped up root cause analysis. Stijn explained:
"If the Marketing data product has an issue, that may be fine. However, if the Attribution data product within Marketing has an issue, we must immediately jump on it."
Use Dead Letter Queues (DLQs) to handle failed ingestion events. These queues store metadata like failure timestamps and error types, allowing reprocessing without disrupting the main pipeline. Always store timestamps in UTC and capture both event time and ingestion time to measure processing delays accurately. Automated lineage tracking is another must-have - it quickly identifies downstream impacts when an upstream source fails.
For GraphQL-based systems, limit query depth and complexity to prevent server overload from poorly written queries. Distributed tracing tools like OpenTelemetry can track data flow across microservices, while structured logs make automated analysis easier. Keep in mind, a 99.9% SLA allows only 43 minutes of downtime per month, whereas a 99% SLA permits up to 7.2 hours - set your thresholds accordingly.
Using LeadBoxer in Developer-First Data Layer Design
LeadBoxer’s API-first design is built to align with developer-first principles. Instead of spending months creating custom pipelines, teams can integrate LeadBoxer and have it up and running in just days. The platform takes care of tracking, enrichment, and infrastructure, allowing developers to dedicate their time to enhancing core product features.
Integrating LeadBoxer with Your Data Layer
LeadBoxer provides three integration options tailored to different technical needs. You can choose from:
A script tag for a quick and simple setup.
An NPM package for direct web tracking.
A server-side API for advanced control and CRM updates.
For teams working with custom data science pipelines, LeadBoxer also supports raw event streaming via API or storage.
Security is built into the platform, with features like tenant isolation, API key scoping, and GDPR-compliant EU hosting. If you’re building vertical SaaS or embedded analytics solutions, the white-label option lets you use custom domains, presenting the data layer as part of your brand. Plus, the pricing is flexible - your first 50,000 credits are free, and pay-per-use rates start at $0.0005 per credit for volumes between 50,000 and 1 million.
This integration framework lays the foundation for advanced lead management capabilities.
Using LeadBoxer for Lead Qualification and Management
LeadBoxer simplifies lead qualification and management by leveraging its robust data layer design. It distinguishes between three types of data:
Declared data: Information provided by users.
Enriched data: Details obtained from third-party APIs.
Inferred data: Insights deduced from IP addresses or user behavior.
The platform automates this process, identifying companies through IP tracking, analyzing page behavior, and enriching records with firmographic data, persona detection, and Ideal Customer Profile (ICP) fit signals.
Once processed, the platform delivers qualified insights that are scored, filtered, and ICP-aligned. These insights can be seamlessly integrated into dashboards or workflows, supporting the developer-first approach. For real-time lead routing, LeadBoxer’s synchronous API calls - boasting response times under 500ms - enable instant qualification during form submissions.
"Lead enrichment isn't an ops task. It's a revenue multiplier - one of the few systems that, when designed well, quietly improves performance across every stage of the funnel." – LeadOps
Beyond qualification, LeadBoxer enhances efficiency by enabling automated workflows.
Automating Workflows with LeadBoxer
LeadBoxer brings automation to lead enrichment through programmatic control. Its APIs trigger webhooks as soon as a lead enters a CRM, delivering enriched data in milliseconds for immediate routing.
The platform supports both synchronous workflows for real-time routing and asynchronous workflows via webhooks for handling high-volume background enrichment. This flexibility aligns with modular and scalable development practices.
Using enriched fields like geography or company size, teams can set up instant alerts or automatically assign leads to the right owner. Additionally, LeadBoxer’s Intelligence APIs provide external market data, such as firmographics and intent signals, while its Integration APIs ensure smooth syncing with internal systems like HRIS or CRM. This separation allows developers to create adaptable automation workflows that evolve with business needs.
Building a Developer-First Future for B2B SaaS
Key Lessons from Developer-First Design
Shifting to developer-first data layers isn't just about technical tweaks - it’s a core strategy for driving digital business growth. By designing the API contract before diving into implementation, teams establish a single source of truth that enables frontend and backend developers to work simultaneously. This approach not only speeds up the development process but also minimizes engineering overhead, making it a win-win for efficiency and collaboration.
The advantages don't stop at faster development. Decoupling the data layer from the presentation layer allows businesses to serve multiple platforms - whether it's web, mobile, or even future technologies - all from a single foundation. This adaptability eliminates the need for constant re-architecture. For instance, companies using embedded integration platforms have reported reducing integration-related engineering time by up to 95%. On top of that, some B2B SaaS providers have achieved a 50% boost in new customer acquisition by cutting down the time spent on integration maintenance.
Additionally, treating your API as a product brings built-in advantages like security, scalability, and modularity. These aren't just afterthoughts - they become fundamental features. By focusing on API design and management, you not only reduce technical debt but also open doors to new revenue streams through usage-based pricing models and partner ecosystems. These lessons provide a clear roadmap for creating a more efficient and scalable platform.
Next Steps for Implementing Your Data Layer
To fully unlock these benefits, start by defining your API specification using tools like OpenAPI or AsyncAPI before writing a single line of code. Deploy mock servers early in the process to test functionality and integrate linting tools into your CI/CD pipeline to catch issues before they escalate. For version control, adopt semantic versioning (e.g., /v1, /v2) to avoid breaking changes, and use idempotency keys for critical operations to ensure reliability.
Tracking metrics is equally important. Focus on "Time to First Successful API Call" as a key indicator of your developer experience. This metric highlights how quickly developers can integrate with your platform, which directly impacts user satisfaction. Lastly, fostering cross-team alignment will enhance the overall developer experience and help mitigate integration challenges. By following these steps, your platform will be well-positioned to adapt to evolving developer needs and market trends.
FAQs
What are the main advantages of using an API-first approach in B2B SaaS platforms?
An API-first approach offers multiple advantages for B2B SaaS platforms. For starters, it speeds up development cycles by letting teams work on and test components independently. This means developers can focus on their specific tasks without waiting on others, making the process more efficient.
It also prioritizes developer experience by ensuring APIs are user-friendly and compatible with tools they’re already familiar with. This can save time and reduce friction during implementation.
On top of that, an API-first strategy boosts scalability and adaptability, making it easier to adjust and expand your product as your business evolves. It encourages smoother collaboration between teams and ensures consistent data handling, which helps simplify workflows and improve overall system performance.
How does modularity help make a data layer more scalable?
Modularity boosts the scalability of a data layer by enabling individual components to be managed and updated independently. This approach allows you to make changes, perform maintenance, or introduce new features without disrupting the entire system.
When the data layer is divided into smaller, self-contained modules, managing growth becomes far more efficient. Troubleshooting is simpler, and adapting the system to meet new demands becomes less of a challenge. This setup ensures the system remains flexible and performs well over time.
What are the key security practices for building a developer-focused data layer?
To keep sensitive data safe and maintain secure integrations, a developer-first data layer needs strong security measures. Start with solid authentication and authorization controls. For example, implement role-based access control (RBAC) and fine-grained permissions to ensure users only access what they need. Use token-based authentication methods like OAuth 2.0, encrypt data both during transit and while stored, and apply rate limiting to prevent misuse or attacks.
Other important practices include enabling Row Level Security (RLS) for more precise database access control, setting up private schemas to protect sensitive information, and conducting regular security audits to identify and address potential issues. Continuous monitoring and following API design best practices are also essential steps to minimize vulnerabilities. By layering these protections, you can balance developer usability with maintaining data security and integrity.
Related Blog Posts

Supercharge your marketing results with LeadBoxer!
Analyze campaigns and traffic, segement by industry, drilldown on company size and filter by location. See your Top pages, top accounts, and many other metrics.


LeadBoxer
Get started